Robust Mobile Fixation Detection for Head-mounted Eyetracker
[Nov 2022]
see demo ↗
My Contribution
- Designed and developed the prototype architecture of a custom fixation detection method using foveate image patches.
- Analyzed data to measure the performance of the detection methods in marking and classifying fixation events.
Project Summary
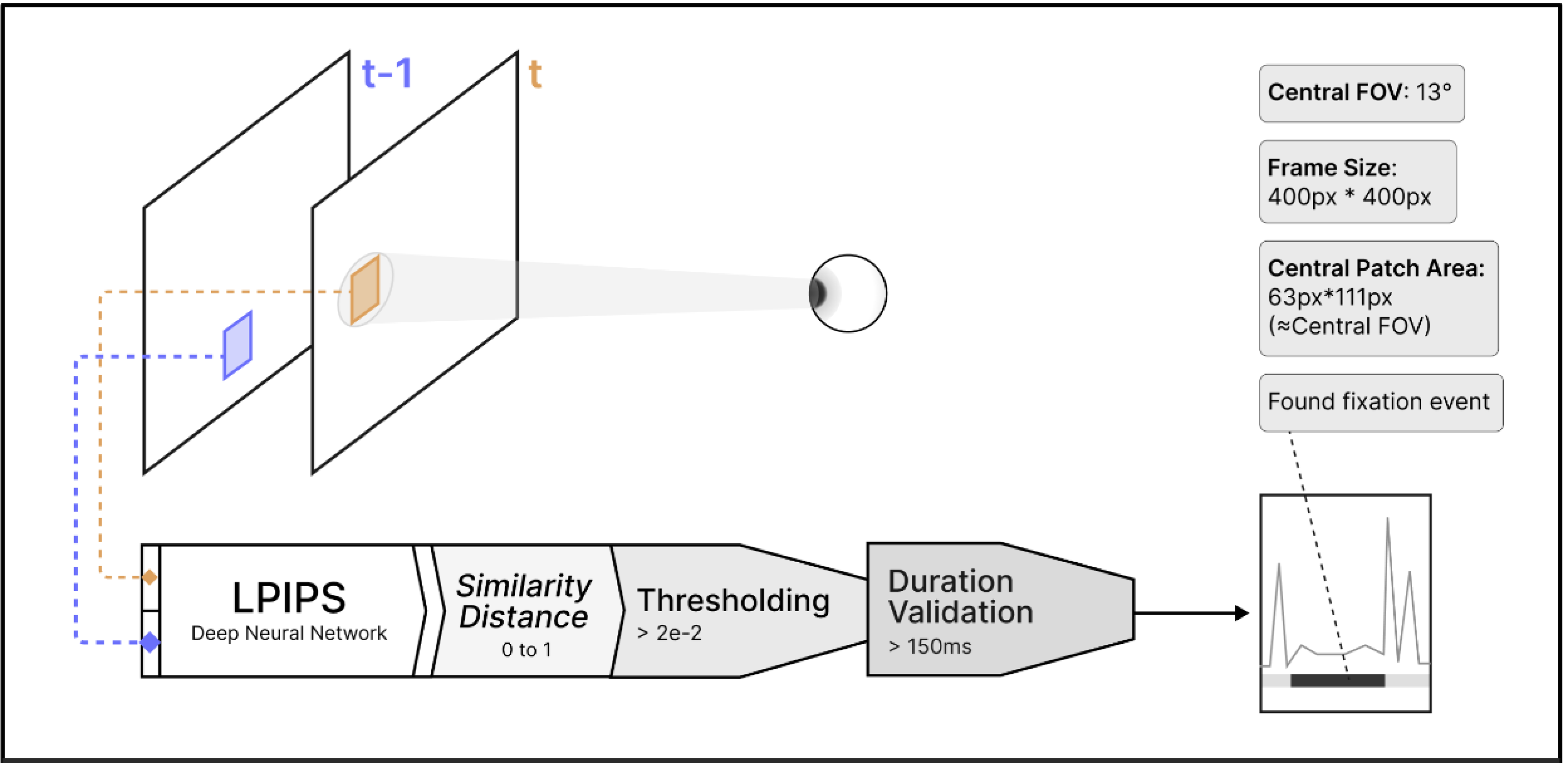
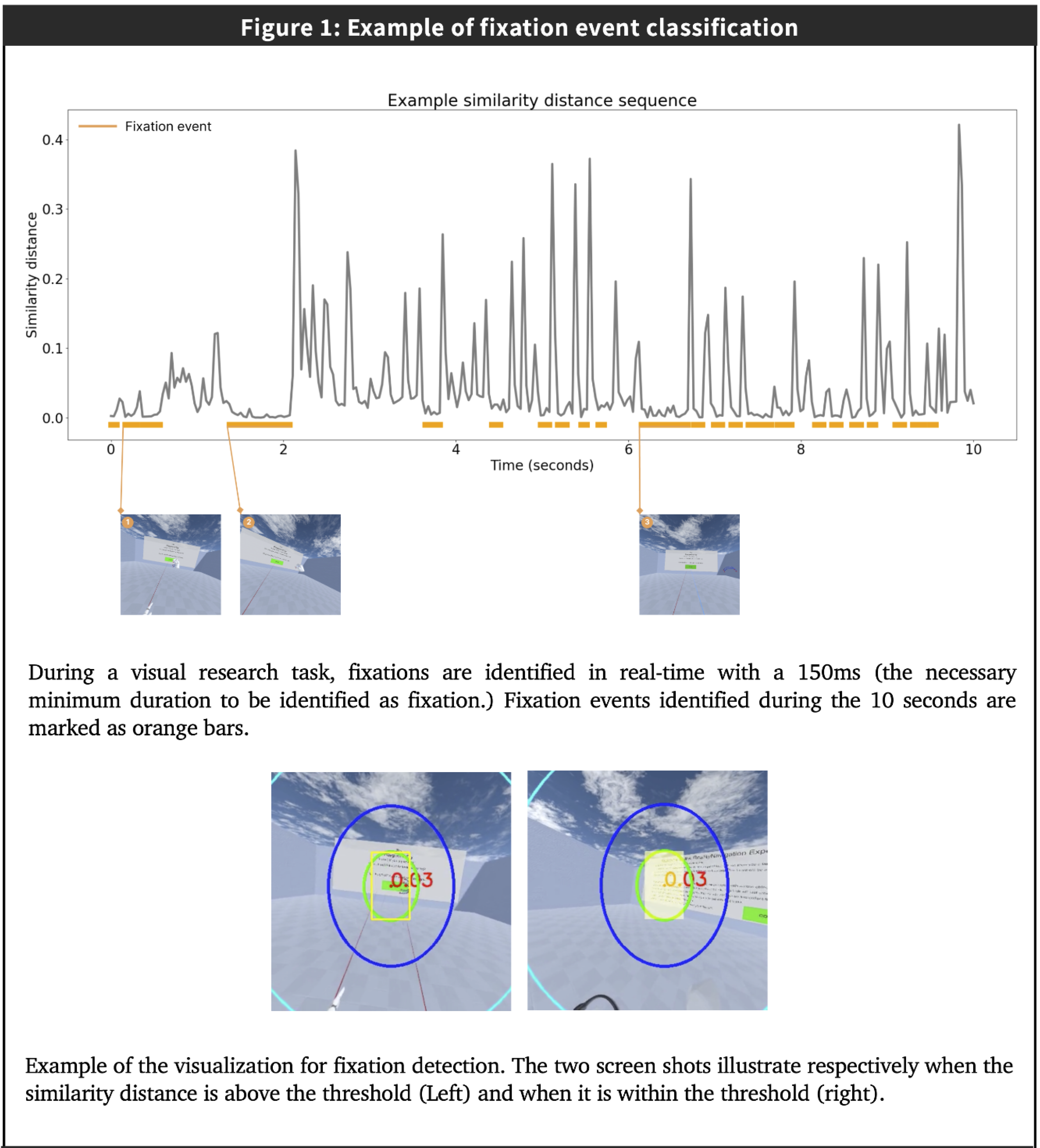
(figures are at the bottom of the page.)1. Motivation
Humans take in visual information from the world through discrete gaze-behavior events — Fixations. Reliably detecting fixations enables studying the downstream neural processing of perceived visual stimuli, and reveals the attentional state of an individual. Fixation detection is crucial in eye-tracking metrics for psychophysics and neural science research. Though its algorithm is well-established for desk- mounted eyetracker where minimal head movement is involved. Identifying fixations for more ecologically valid head-mounted eyetracker is still an open problem given the head and body freely of the user’s volition.
2. Contributions of this work
-
We develop a robust fixation detection method for contemporary mobile eye-
tracking platforms such as virtual and augmented reality (VR and AR) to solve the
challenge of detecting fixation free-roaming scenarios.
-
Our approach uses image patches of the foveate
area instead of the gaze estimation used in velocity and dispersion-based detection
methods.
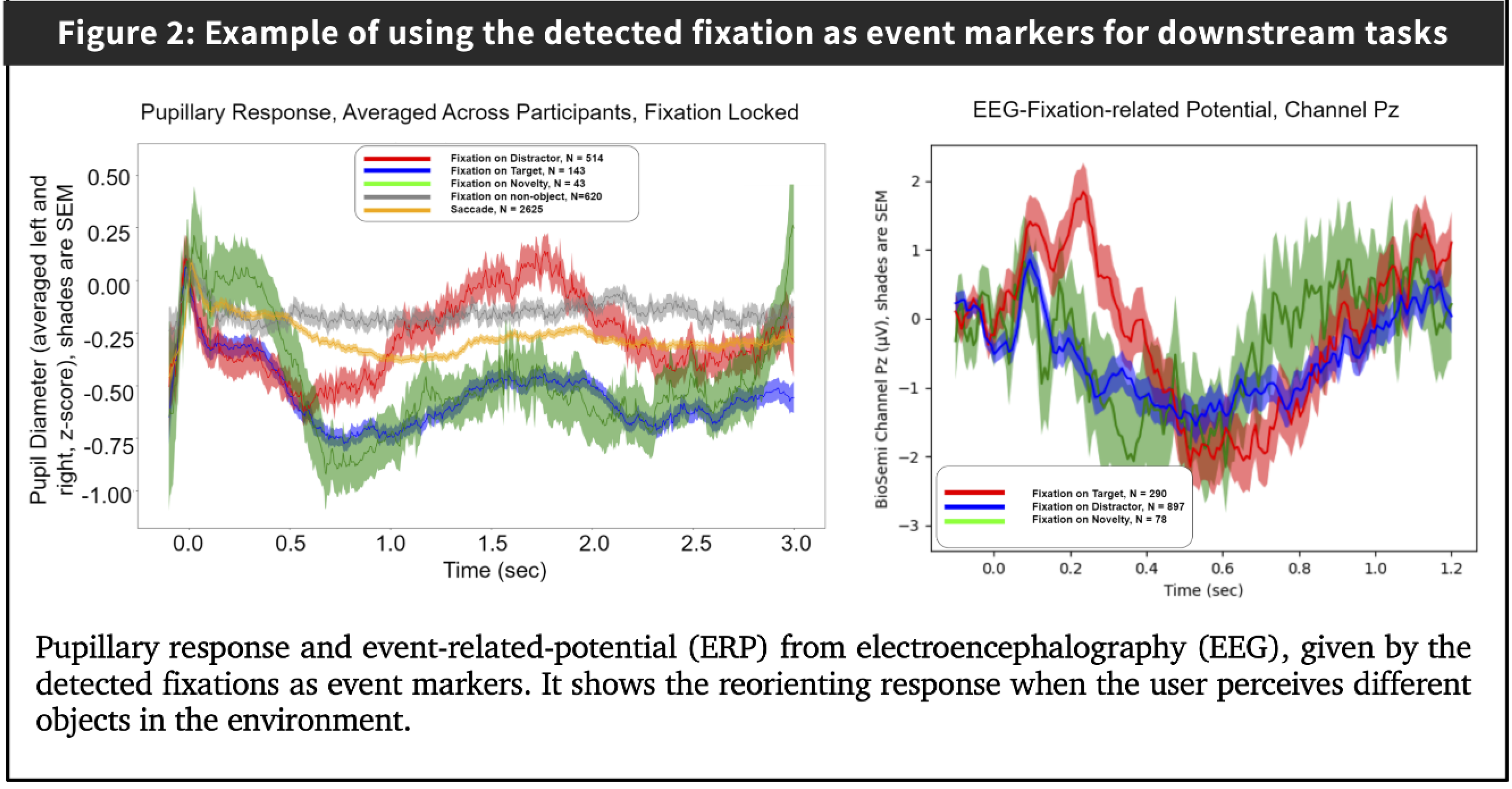
- We provide a platform-independent fixation detection algorithm that can enable various downstream applications, such as providing event-markers for decoding event-related potential (ERP) for brain-computer interface (BCI).
3. Conclusion and future directions
1) This method is part of efforts to make a platform-independent tool for HCI, biomedical neuroscience, and cognitive science researchers. Our future work will focus on integrating the algorithm into the brain-computer interface, enabling implicit interaction user state monitoring. -> See PhysioLabXR
2) Gaze-based interaction can be classified into four categories: diagnostic (for assessment of expertise), active (gaze as pointers in virtual interfaces), passive (for reactive manipulation of scene elements), and expressive (for creative purposes). We hope to explore more use cases in active and expressive gaze-based interaction
3) In addition to gaze patches from video data, gaze estimation and velocity can be used for a multi-modal gaze behavior classifier. The model can be extended to capture more classes of gaze behaviors, including micro- saccades, drifts, and smooth pursuits.
4) The model uses fixed parameters for the similarity thresholding and minimal fixation duration. A future direction is to change them to learnable parameters and estimate their value from a labeled eyetracking dataset.
Hannah Tongxin Zeng 1; Ziheng ‘Leo’ Li 2; Steven Feiner 2; Paul Sajda 3,4,5
LIINC Lab
Laboratory for Intelligent Imaging and Neural Computing ↗
CGUI Lab
Computer Graphics and User Interfaces Laboratory ↗
1: Barnard College, Columbia University
2: Columbia Department of Computer Science
3: Columbia Biomedical Engineering
4: Columbia Electrical Engineering
5: Columbia Radiology (Physics)
LIINC Lab
Laboratory for Intelligent Imaging and Neural Computing ↗
CGUI Lab
Computer Graphics and User Interfaces Laboratory ↗
1: Barnard College, Columbia University
2: Columbia Department of Computer Science
3: Columbia Biomedical Engineering
4: Columbia Electrical Engineering
5: Columbia Radiology (Physics)